Investigating Discrete Distributions
Sampling
Say you want to get an idea of how many siblings each HSC student has. This is a naturally occurring discrete distribution. However there is no formula that describes it.
You can't ask every student how many siblings they have because there are too many. So the next best thing would be to ask a small percentage of students. This small percentage is called a sample.
So for each student in the sample, you would record the number of siblings. The number of siblings is called the score, and when speaking in general about a score, it is represented as x.
There are several ways to describe and/or summarise samples. Each method contributes to building a picture of the distribution.
Frequency Tables
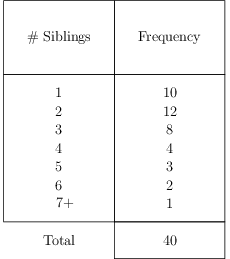
A frequency table lists the number of occurrences of each score against the score. Here is a hypothetical frequency table for the sibling sample above.
Frequency Histograms
A frequency histogram displays the frequencies as a bar chart.
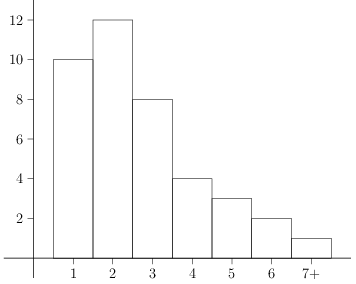
Both the frequency table and histogram provide general information about the distribution - things like what would be the most likely score, and how spread out are the scores.
Sample Mean
The mean is the average of the scores. It is an indication of what would be the most likely score if you selected a student at random. Calculate the mean by adding all the scores then dividing by the number of scores. \[ \begin{align} \text{Mean} &= \frac{x_1+x_2+\ ...\ + x_N}{N} \\ \bar x &= \frac{\sum_{i=1}^N (x_i)}{N} \end{align}\ \] where N is the number of scores. Using a frequency table, this is \[ \begin{align} \bar x &= \frac{\sum_{i=1}^n (f_i \times x_i)}{N} \end{align}\ \] where n is the number of rows in the frequency table and N is the sum of the frequencies.
For the sibling sample, the mean is \[ \begin{align} \bar x &= \frac{108}{40} = 2.7 \end{align}\ \]
Sample Variance
Variance is a measure of how spread out the scores in a sample are. The variance is calculated using the mean of the data as a sort of reference point:
\[ s^2 = \frac{\sum_1^N (x_i-\bar x)^2}{N-1} \ \]
where, \( \bar x \) is the mean and N is the number of scores. The factor of N-1 and not N is a theoretical requirement. Using a frequency table, the expression becomes \[ s^2 = \frac{\sum_1^n f_i \times (x_i-\bar x)^2}{N-1} \ \] where n is the number of rows in the frequency table.
The quantity \( (x_i-\bar x) \) is called the deviation of score \( x_i \) from the mean. The numerator is the 'sum of the squares of the deviations from the mean'. Note that the sample variance is approximately (due to the factor of N-1 and not N) the average of the squares of the deviations from the mean.
For the sibling sample, the variance is \[ \begin{align} s^2 &= \frac{98.40}{39} = 2.52 \quad \end{align} \]
 Throw a die ten times and record the outcomes. Calculate the sample mean. Calculate the sample variance.
Throw a die ten times and record the outcomes. Calculate the sample mean. Calculate the sample variance.
Throw a die twenty times and record the outcomes. Calculate the sample mean. Calculate the sample variance. What can you say about the sample variance in the two cases?
Guided Examples
O E Qs
Sampling From a Known Distribution
Unlike the distribution of the number of siblings, other discrete distributions like the uniform and binomial distributions can be described by a formula or rule. This means you can generate samples as required, rather than finding a real world process to obtain the sample. There are two ways to do this
- By hand - for example, by throwing one or two dice, tossing three coins etc
- Computer simulation - spreadsheets and programming languages have random number generators so instead of throwing two dice, say, you can genarate two random numbers between 1 and 6.
Example - sum of two dice
Frequency table
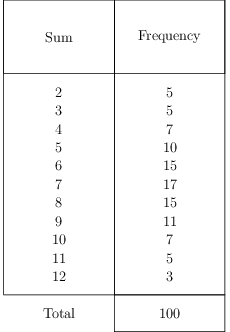
Here is a frequency table generated using two random number generators generating a random integer between 1 and 6, and recording their sum, repeated 100 times.
Histogram
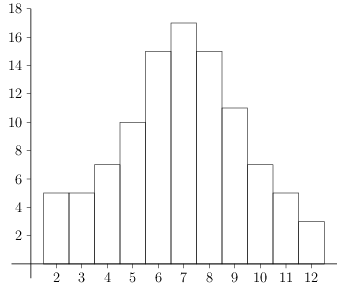
Here is the associated histogram.
Mean
The sample mean is \[ \begin{align} \bar x &= \frac{692}{100} = 6.92 \end{align}\ \]
Variance
The sample variance is \[ \begin{align} s^2 &= \frac{599.36}{99} = 6.05 \end{align}\ \]
Use a spreadsheet to repeat the above experiment. Comment on the difference between the results.
The lesson on Properties of Discrete Distributions shows you how to calculate these two statistics for this distribution exactly.
A Note on Calculations
To calculate the mean and standard deviation you first need to calculate the total score and the sum of the squares of the deviations. This is most easily done by a table :
| \( x_i \) | \( f_i \) | \( x_i f_i \) | \( f_i(x_i-\bar x)^2 \) |
| 2 | 5 | 10 | 121.032 |
| 3 | 5 | 15 | 76.832 |
| ... | ... | ... | ... |
| 12 | 3 | 36 | 77.420 |
| 6.92 | 6.05 |
A spreadshheet is good for this type of calculation. You can arrange the data in columns or rows as you prefer.
Most calculators will calculate the mean and standard deviation from the data.